prerequisites :
- Mac OS X 10.9.4 or higher
- java 1.6
- hadoop 2.2.0 or higher
Basic knowledge on terminal commands will definitely useful as well. :)
Create a separate user for hadoop
Even though it’s not required to create a user and a user group it’s recommended to separate hadoop installation from other applications and user accounts on the same machine.
- goto System preferences ->user and user groups
- unlock the window and create a group name 'hadoop'
- create a user name 'hduser'
- click on newly created hadoop group and select the hduser to add hduser to hadoop group.
This can be done in terminal but for some reason in mac os x linux commands didn't work for me.
log in as hduser.
SSH Configuration for hadoop
Hadoop need ssh to connect with it’s nodes. we need to configure ssh connection to localhost with hduser logged in.
ssh should be installed on your machine to proceed. There are plenty of tutorials out there how to install ssh on mac.
1. Generate ssh key for hduser
log in as hduser.
Generate ssh key for hduser.
it’s not recommended to RSA key pair with empty password.But this way you don’t have to enter the password every time hadoop communicate with it’s nodes.
Now ssh should work fine with localhost.
Optional :
If you face any conflicts with local resources it's good idea to force hadoop to use IPv4.
add following line in {hadoop_2.2.0_base}/etc/hadoop/hadoop-env.sh
Add hadoop binary path to system PATH variable so you can access them system wide.
Create two directories from hduser to hold name node and data node information on hdfs filesystem.
Edit following configurations in {hadoop base directory}/etc/hadoop .
/etc/hadoop/core-site.xml
/etc/hadoop/hdfs-site.xml
/etc/hadoop/yarn-site.xml
/etc/hadoop/mapred-site.xml
If everything went correctly you will see something similar as following. (i have removed some classpath for clarity)
It's good practice to start each process one after another as it will be easy to debug if something goes wrong.
Start the namenode
Use jps tool to see if namenode process started successfully.
Start datanode
Start node manager
If everything went correctly, you will see all the VMs started in jps as follows.
Troubleshooting for Mac OS X :
If you facing issues in mac os x add following lines to hadoop-env.sh as well.
1. "Unable to load realm info from SCDynamicStore put: .." when starting a namenode.
This is a known issue of hadoop. There's a open jira for this issue as well.
https://issues.apache.org/jira/browse/HADOOP-7489
2. "Can't connect to window server - not enough permissions." When formatting a name node.
This is a java error specific to Mac os x. Add following lines and use Headless mode in hadoop.
Refer http://www.oracle.com/technetwork/articles/javase/headless-136834.html for more information.
3. If you unable to start any process refer the logs generated by hadoop in log directory. These logs are very descriptive therefore logs will be helpful to pin point issues.
Hadoop comes with web interfaces which shows current statuses of hdfs and map reduced tasks.
1. See the status of HDFS name node. http://localhost:50070

2. See the status of HDFS secondary name node. http://localhost:50090
it’s not recommended to RSA key pair with empty password.But this way you don’t have to enter the password every time hadoop communicate with it’s nodes.
Now we are ready to enable ssh connection to your local machine with generated key. move into .ssh directory by,
Then copy the public key from id_rsa.pub to authorized_keys using following command.
finally we are ready to connect through ssh.
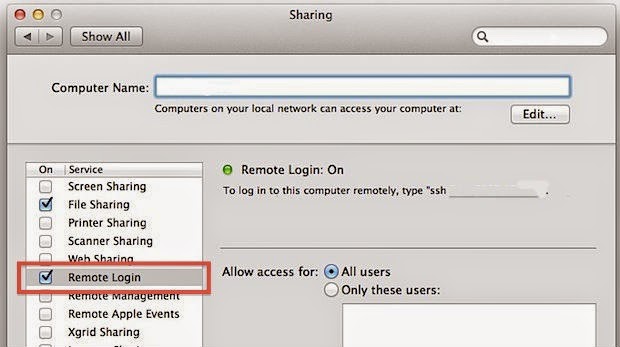
If you getting connection refuse error probably mac has turn of remote login to your machine. Goto system preferences-> sharing-> check on remote login. Refer following screenshot.
Now ssh should work fine with localhost.
Optional :
If you face any conflicts with local resources it's good idea to force hadoop to use IPv4.
add following line in {hadoop_2.2.0_base}/etc/hadoop/hadoop-env.sh
Hadoop configurations
Extract downloaded hadoop 2.2.0 and move hadoop directory to /system/ or any globally accessible directory. I have moved it to /hadoop/ directory in the machines file system.
Make sure to give hduser ownership of the Hadoop directory using following command.
Execute following command and open bashrc for hduser.
Execute following command and open bashrc for hduser.
Add hadoop binary path to system PATH variable so you can access them system wide.
make sure to change the JAVA_HOME to your JAVA_HOME path. Before proceed check if these environment variables are set. if not it's better to restart the computer and make sure all variables are set properly.
If by any chance you don't know where's your java path just add following JAVA_HOME command and mac will set the latest availabe java home path to environment variable.
Export following variables to /hadoop-2.2.0/etc/hadoop/hadoop-env.sh
Edit following configurations in {hadoop base directory}/etc/hadoop .
/etc/hadoop/core-site.xml
/etc/hadoop/hdfs-site.xml
/etc/hadoop/yarn-site.xml
/etc/hadoop/mapred-site.xml
Finally we can format the name node of hadoop by executing following.
If everything went correctly you will see something similar as following. (i have removed some classpath for clarity)
Starting Hadoop file system and yarn
It's good practice to start each process one after another as it will be easy to debug if something goes wrong.
Start the namenode
Use jps tool to see if namenode process started successfully.
Start datanode
Start node manager
Start history server
If everything went correctly, you will see all the VMs started in jps as follows.
Troubleshooting for Mac OS X :
If you facing issues in mac os x add following lines to hadoop-env.sh as well.
1. "Unable to load realm info from SCDynamicStore put: .." when starting a namenode.
This is a known issue of hadoop. There's a open jira for this issue as well.
https://issues.apache.org/jira/browse/HADOOP-7489
2. "Can't connect to window server - not enough permissions." When formatting a name node.
This is a java error specific to Mac os x. Add following lines and use Headless mode in hadoop.
Refer http://www.oracle.com/technetwork/articles/javase/headless-136834.html for more information.
3. If you unable to start any process refer the logs generated by hadoop in log directory. These logs are very descriptive therefore logs will be helpful to pin point issues.
Hadoop Web Interfaces
Hadoop comes with web interfaces which shows current statuses of hdfs and map reduced tasks.
1. See the status of HDFS name node. http://localhost:50070
2. See the status of HDFS secondary name node. http://localhost:50090
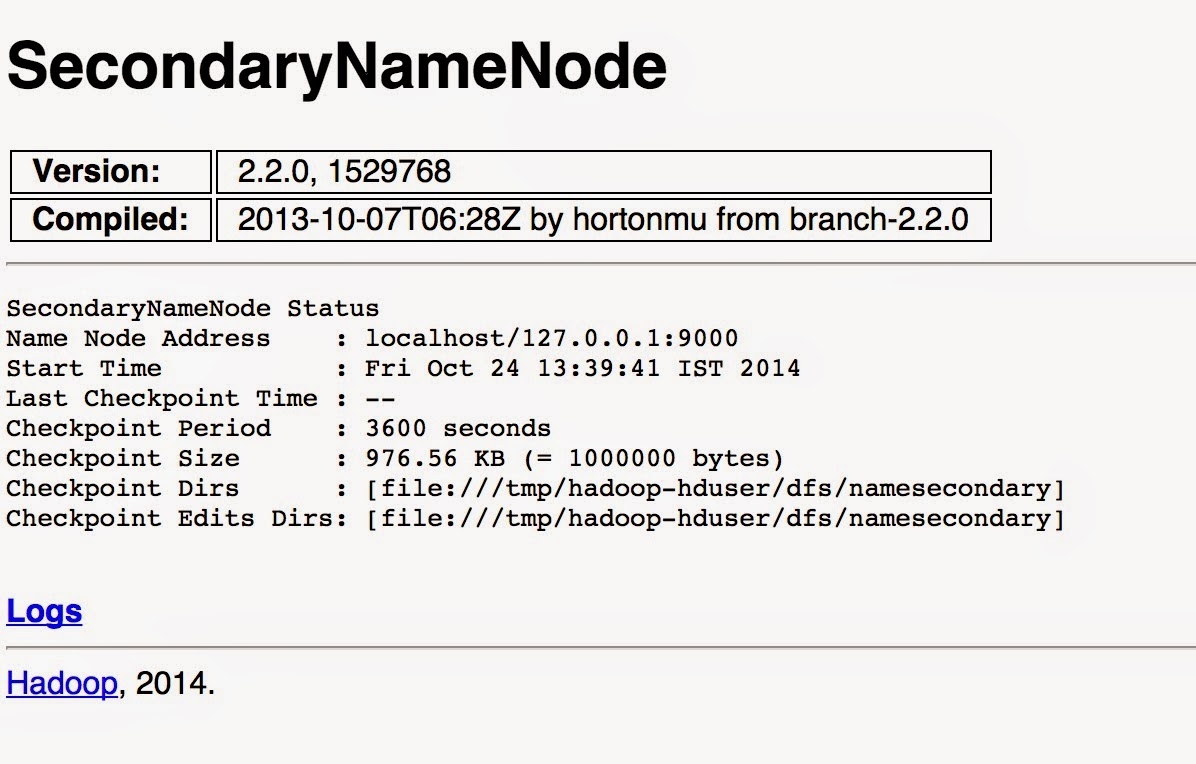
3. See hadoop job history http://localhost:19888/

If you can access these web interfaces that means hadoop has configured correctly on you machine with a single node. If there's any questions feel free to ask on comments bellow.
Good luck..!!